Which is more important, line coverage or branch coverage?

I've been setting up code coverage for some of my clients' projects and some of my own open source projects, like Clean Architecture and Specification (100%!) and Guard Clauses (99%...). I wrote up how to configure Azure DevOps to generate code coverage reports that properly merge the results from multiple test projects using ReportGenerator. When you look at a code coverage report, whether its run in the console or online, you'll frequently see metrics like these:
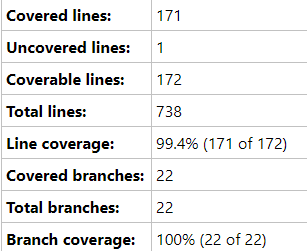
Testing Code Coverage Metrics
Notice the two metrics, line coverage and branch coverage. You can see how they are calculated. Take the Cover lines and divide that into the Coverable lines and you get the line coverage percentage. Take the covered branches and divide that into the total branches and you have branch coverage as a percentage. But which one is "better", line coverage or branch coverage? And what's a good percentage to aim for, really?
Ok, I'm not actually going to answer that last question here, because that can be its own article, but we will look at branch coverage versus line coverage and which one you should focus on.
Line Coverage Is More Granular!
Obviously if you hit every single line, that should be more important than if you hit every branch, right? Some tools will measure method and class coverage, letting you know what percentage of classes your tests might have hit even if only one test did one minor thing with the class. I'm skeptical of the value of knowing I have high class or method coverage when I have no idea how much of the actual code in those methods or classes was tested. And just the same, clearly, measuring how many lines of code were tested should be more important than how many branches were covered.
So, that's it. We're done here. Line coverage wins. Stop bothering to calculate branch coverage.
Not so fast...
It turns out branch coverage is actually also important.
Let's consider an example. This is taken from this excellent Stack Overflow answer.
public int GetNameLength(boolean isCoolUser)
{
User user = null;
if (isCoolUser)
{
user = new John();
}
return user.getName().length();
}
Here's a C# or Java method that takes in one parameter and that contains a single if statement. Its cyclomatic complexity is 2, because there are exactly two paths through this method. That means its Total branches is also 2. If the parameter isCoolUser is true, every line of this method will be executed.
So, let's say you write a single test that calls this method, passes it a value of true, and asserts that it returns the expected integer value. Now you calculate code coverage. Your test hit every line, so you have 100% line coverage. And you hit the true case for the if condition but not the false case, so your branch coverage is 1 out of 2 or 50%.
So what? Well, it turns out that if you ship your code with just one test (and 100% line coverage, remember!), you'll be shipping a bug that occurs whenever you pass false to the method. The last line will result in a null reference exception because user will be null.
Measure Both
I do think line coverage is more important than branch coverage, because it's more granular. But it doesn't replace branch coverage. You need both. And because branch coverage is generally easier to achieve than line coverage, it should be pretty easy (if you're monitoring it) relative to line coverage to get branch coverage up to whatever goal you've set.
Do you measure code coverage? Which flavor? Leave a comment below or on twitter via this tweet:
Which is more important, line coverage or branch coverage?https://t.co/ThwEhqWyEf#programming #testing #codecoveage #cleancode #CodeNewbie
— Steve "ardalis" Smith (@ardalis) August 27, 2019
Category - Browse all categories

About Ardalis
Software Engineer
Steve is an experienced software architect and trainer, focusing currently on ASP.NET Core and Domain-Driven Design.
